") millis
millisUNIX time
Convert milliseconds
to UTC time & date:
to local time & date:

| System.currentTimeMillis() example long millis = System.currentTimeMillis(); System.out.println(millis); // prints a Unix timestamp in milliseconds System.out.println(millis / 1000); // prints the same Unix timestamp in seconds As a result of running this 2 numbers were printed: 1426349294842 (milliseconds) and 1426349294 (seconds). Alternatively, you can use code such as the one below to obtain a Calendar object that you can work with: That will print a human readable time in your local timezone.
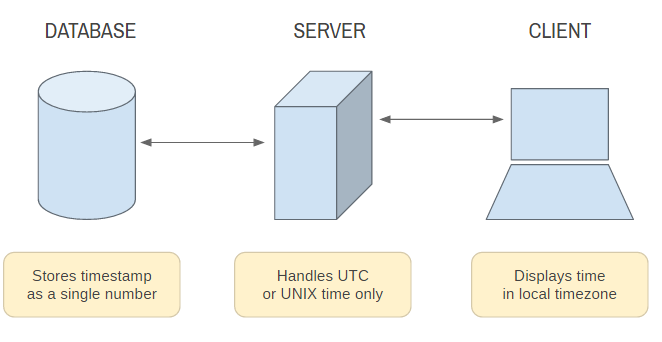
To understand exactly what System.currentTimeMills() returns we must first understand: what UTC is, what UNIX timestamps are and how they form a universal time keeping standard. | ||||||||||||||||||
| What is UTC? UTC is the main universal time keeping standard. It stands for Coordinated Universal Time. People use it to measure time in a common way around the globe. Since it is essentially being used interchangeably with GMT (Greenwich Mean Time) you could think of it as the timezone defined around the Greenwich Meridian a.k.a. the Prime Meridian (0° longitude): ") The current UTC date/time is . Your local time is | ||||||||||||||||||
| What is a UNIX timestamp? A UNIX timestamp, also known as Epoch Time or POSIX timestamp, is a representation of a moment defined as the time that has elapsed since a reference known as the UNIX epoch: 1970-01-01 00:00:00 UTC (what is UTC). Using Java as an example, System.currentTimeMillis() returns just that, a UNIX timestamp in milliseconds - UNIX timestamps will often be measured in seconds as well (but System.currentTimeMillis() will always be in milliseconds). Following is a table that unifies these concepts:
You can therefore say that on 2015-03-07 16:00 UTC, 1425744000000 milliseconds (or 1425744000 seconds) have passed since 1970-01-01 00:00:00 UTC. Note that System.currentTimeMillis() is based on the time of the system / machine it's running on. In conclusion, the UNIX timestamp is just a system / format for representing a moment in time. Check out some other date / time systems. |
||||||||||||||||||
| UNIX timestamps, UTC & timezones One of the most important things to realize is that 2 persons calling System.currentTimeMillis() at the same time should get the same result no matter where they are one the planet:  The 'snapshot' above represents the same moment from 4 different perspectives: John's timezone, Juliette's timezone, UTC (Coordinated Universal Time) and milliseconds from the Unix epoch. | ||||||||||||||||||
Millisecond relevance & usage
|
||||||||||||||||||
| Instant.now().toEpochMilli() This is an API introduced with Java 8 and probably promoted as a modern replacement for legacy time-keeping code. In this context, essentially, Instant.now().toEpochMillis() would be an upcoming equivalent for System.currentTimeMillis(). To replicate the original Java example that we gave, this is how the UNIX timestamp would be obtained: Instant now = Instant.now(); long millis = now.toEpochMilli(); System.out.println(millis); // prints the UNIX timestamp in milliseconds or in one line: System.out.println(Instant.now().toEpochMilli()); Getting an Instant back from the milliseconds (instead of a Calendar) can be done like this: Instant instant = Instant.ofEpochMilli(millis); System.out.println(instant.toString()); // not much can be done with the Instant itself, except for printing a UTC time ZonedDateTime zonedDateTime = instant.atZone(ZoneId.systemDefault()); System.out.println(zonedDateTime.getHour() + ":" + zonedDateTime.getMinute()); // prints local time OffsetDateTime offsetDateTime = instant.atOffset(ZoneOffset.UTC); System.out.println(offsetDateTime.getHour() + ":" + offsetDateTime.getMinute()); // prints UTC time However, for the sake of intense usage, my experiments show that Instant.now().toEpochMilli() is approximately 1.5 times slower than System.currentTimeMillis(). | ||||||||||||||||||
| Precision vs Accuracy, currentTimeMillis() vs nanoTime() System.currentTimeMillis() offers precision to the millisecond but its accuracy still depends on the underlying machine. This is why, in some cases, it might happen that two subsequent calls can return the same number even if they are in fact more than 1ms apart. The same is true about nanoTime(): precision is down to the nanosecond but accuracy doesn't follow, it still depends on the machine. System.nanoTime(), however, returning nanoseconds, may arguably be better suited to measure deltas (although reportedly a nanoTime() call can be slower than a currentTimeMillis() call - my experiments contradict this: they seem to take exactly the same amount of time). nanoTime()'s disadvantage is it doesn't have a fixed reference point like currentTimeMillis() has the Unix epoch. nanoTime()'s reference might change with a system/machine f67, so from the mentioned methods currentTimeMillis() is the one to use for time-keeping. | ||||||||||||||||||
| UTC vs GMT. The same or different? UTC stands for Coordinated Universal Time. GMT stands for Greenwich Mean Time. UTC is a universal time keeping standard by itself and a GMT successor. A time expressed in UTC is essentially the time on the whole planet. A time expressed in GMT is the time in the timezone of the Greenwich meridian. In current computer science problems (and probably most scientific ones) UTC and GMT expressed in absolute value happen to have identical values so they have been used interchangeably. A detailed analysis reveals that literature and history here are a bit ambiguous. UTC essentially appeared in 1960, GMT being the ‘main thing’ until then. Unlike GMT which is based on solar time and originally calculated a second as a fraction of the time it takes for the Earth to make a full rotation around its axis, UTC calculates a second as “the duration of 9192631770 periods of the radiation corresponding to the transition between the two hyperfine levels of the ground state of the cesium 133 atom”. UTC’s second is far more precise than GMT's original second. In 1972 leap seconds were introduced to synchronize UTC time with solar time. These 2 turning points (different definition of a second and the introduction of leap seconds) ‘forced’ GMT to be the same as UTC based on what seemed a gradual, tacit convention. If you were to calculate true GMT today i would see it based on its original definition of 1 second = 1/86400 days and this would for sure return a different absolute value than what UTC gives us. From this point of view the name “GMT” seems deprecated, but kept around for backward compatibility, traditional timezone based representation of time and sometimes legal reasons. | ||||||||||||||||||
Convert local YYYY / MM / DD
and HH : MM : SS
to milliseconds since epoch: